

Conjunto de datos
El rendimiento se mide sobre un conjunto de nombres de entidades retenidos —excluidos deliberadamente del entrenamiento para que el modelo nunca los haya visto—. Esto garantiza que la evaluación refleje la capacidad de generalización, no la memorización. Para cada nombre, la etapa de recuperación devuelve unos 25 candidatos de la base de datos CB. El rendimiento se mide a nivel de pares de candidatos: cada combinación de nombre y candidato constituye un ejemplo etiquetado.
Dado que solo un candidato por nombre es correcto, el conjunto de datos presenta un fuerte desequilibrio, lo que refleja la distribución del mundo real con la que se encuentra el modelo en producción. El rendimiento se reevalúa con cada ciclo de reentrenamiento semanal.
Matriz de confusión
Lo que mide: El «Matriz de confusión» evalúa el modelo como un clasificador binario en el umbral. Los registros por encima del umbral se clasifican como coincidencias; el resto, como no coincidencias. Resultado:Verdaderos positivos: 1.291.
83.61% de coincidencias reales identificadas correctamente
Falsos positivos — 110
0.29% de coincidencias reales marcadas erróneamente como no coincidentes.
Falsos negativos — 253
16.39% Las coincidencias reales por debajo del umbral se marcan para su revisión.
Valores verdaderos negativos — 37 397
99.71% de las coincidencias falsas reales rechazadas correctamente.
- De las 1544 coincidencias verdaderas del conjunto de prueba, 1291 obtuvieron una puntuación superior al umbral. Los 253 falsos negativos corresponden a coincidencias que obtuvieron una puntuación inferior al umbral de confianza del sistema de gestión de nombres (0.6). En la práctica, Credit Benchmark observa que la coincidencia verdadera sigue figurando en el conjunto de resultados, incluso cuando la confianza en la coincidencia correcta es inferior a 0,6.
- F1 es la media armónica de la recuperación y la precisión: penaliza el desequilibrio entre ambas y premia a los modelos que obtienen buenos resultados en ambas.
- Un F1 de 87.7% refleja un sólido rendimiento general de clasificación en el umbral 0.60: el modelo recupera la gran mayoría de las coincidencias verdaderas, al tiempo que produce pocas predicciones incorrectas.
Curva ROC y precisión-recuerdo
Dado que el conjunto de datos presenta un desequilibrio considerable (~24:1), la curva de precisión-recuerdo constituye el diagnóstico más informativo — El AUC de la curva ROC puede resultar engañosamente optimista en entornos desequilibrados..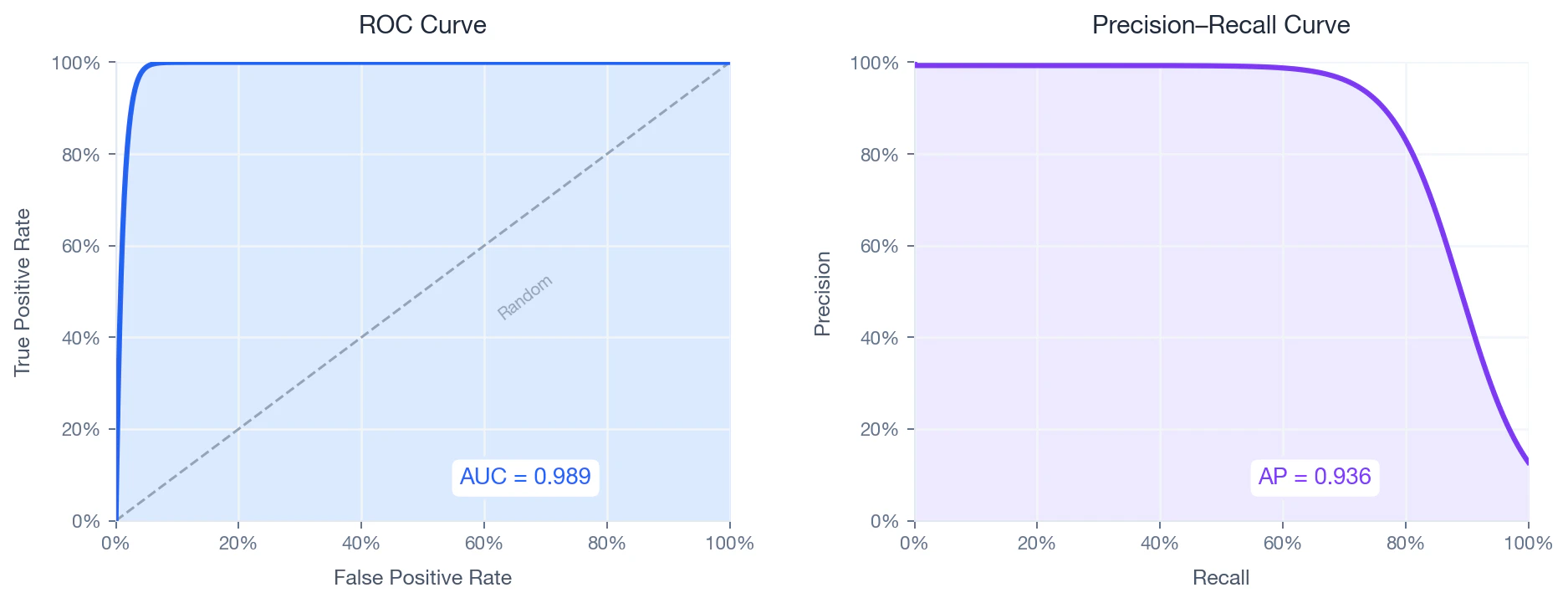
ROC curve (left) and Precision–Recall curve (right) on the held-out test set.
Curva ROC
Lo que mide: la capacidad del modelo para distinguir las coincidencias de las no coincidencias en todos los umbrales posibles. El gráfico «Curva ROC» representa la tasa de verdaderos positivos frente a la tasa de falsos positivos a medida que el umbral varía de 1 a 0:Curva de precisión-recuerdo
Lo que mide: cuánta precisión conserva el modelo a medida que recupera más coincidencias. [Precisión media (AP)](https://en.wikipedia.org/wiki/Evaluation_measures_\(information_retrieval\) #Average_precision) resume esto como el área ponderada bajo la curva PR:- — recuperación en el umbral.
- — precisión en el umbral
Compromiso entre precisión y cobertura
Lo que mide: Precisión La precisión es la proporción de coincidencias previstas que resultan correctas. La cobertura es la proporción de nombres introducidos que reciben una coincidencia por encima del umbral. :- — número de nombres con una puntuación igual o superior a
- — número total de nombres introducidos
- Reducción — a medida que aumentan las coincidencias, la precisión disminuye y la cobertura aumenta.
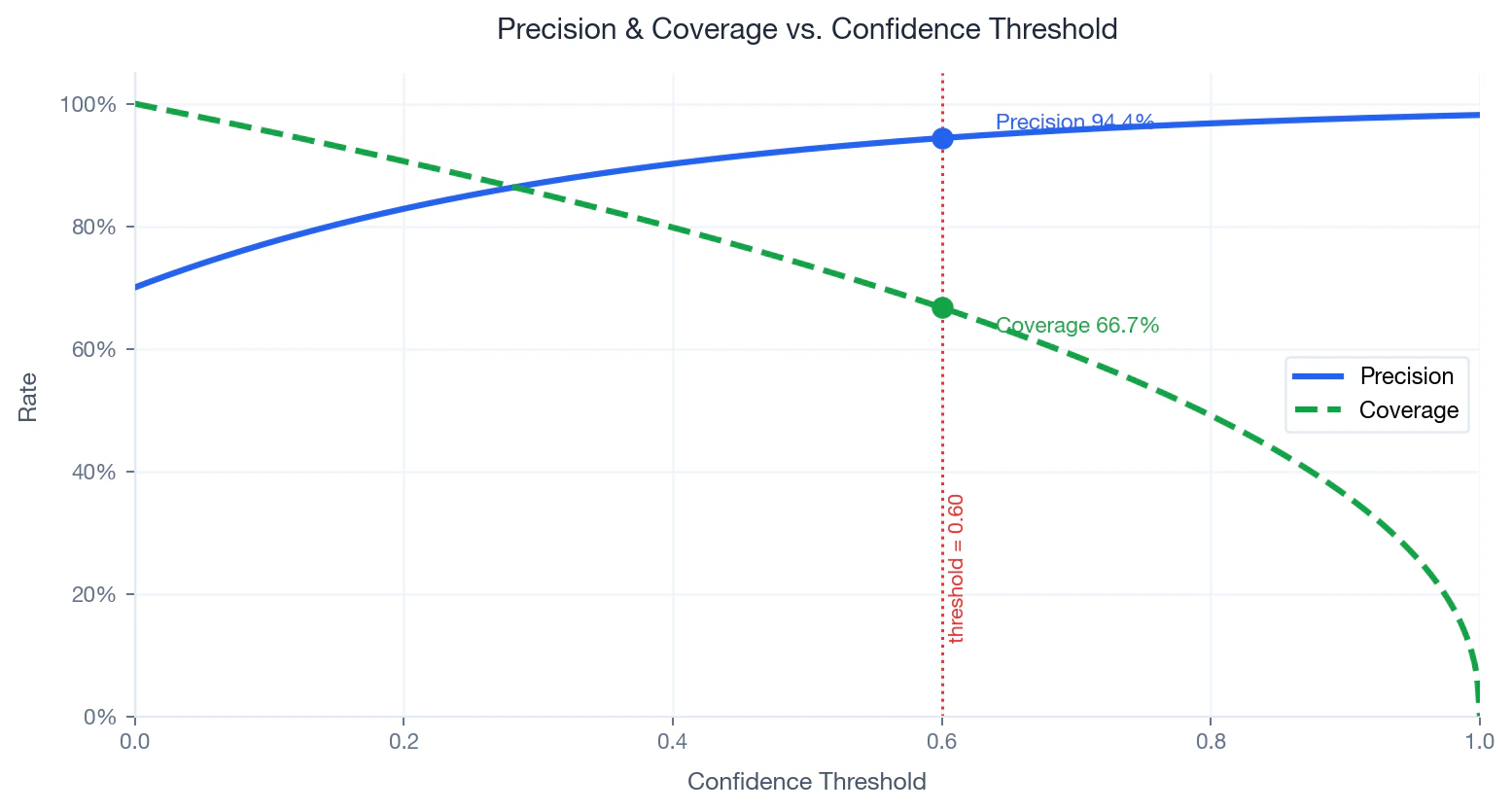
Precision and coverage as a function of confidence threshold. Operating point at 0.60 marked.