

Datasett
Ytelsen måles på et holdt-utenfor-sett med entitetsnavn — navn som bevisst er ekskludert fra opplæringen, slik at modellen aldri har sett dem. Dette sikrer at evalueringen gjenspeiler generalisering, ikke memorering. For hvert navn returnerer hentingsfasen ~25 kandidater fra CB-databasen. Ytelsen måles på kandidatpar-nivå — hver kombinasjon av navn og kandidat er ett merket eksempel.
Fordi bare én kandidat per navn er riktig, er datasettet svært ubalansert — noe som gjenspeiler den virkelige fordelingen modellen møter i produksjon. Ytelsen evalueres på nytt med hver ukentlige omskolingssyklus.
Forvirringsmatrise
Hva det måler: forvirringsmatrise en evaluerer modellen som en binær klassifikator ved terskelen . Kandidater over terskelen forutsies som treff; alle andre som ikke-treff. Resultat:Sann positiv — 1 291
83.61% av faktiske treff som er korrekt identifisert
Falsk positiv — 110
0.29% av faktiske ikke-treff som feilaktig er merket
Falsk negativ — 253
16.39% av faktiske treff under terskelen — fremhevet for gjennomgang
Sanne negative — 37 397
99.71% av faktiske ikke-treff som er korrekt avvist
- Av de 1 544 sanne treffene i testsettet scoret 1 291 over terskelen.
- De 253 falske negativene representerer treff som ble vurdert til å ligge under tillitsgrensen 0.6.
- I praksis finner Credit Benchmark at det sanne treffet fremdeles dukker opp i resultatsettet — selv når sikkerheten for det riktige treffet er lavere enn 0,6.
- F1 er det harmoniske gjennomsnittet av Recall og Precision — det straffer ubalanse mellom de to og belønner modeller som presterer godt på begge.
- En F1-verdi på 87.7% gjenspeiler sterk samlet klassifiseringsytelse ved terskelen 0.60 — modellen gjenfinner det store flertallet av sanne treff, samtidig som den produserer få feilaktige prediksjoner.
ROC-kurve og presisjon–gjenkalling
Fordi datasettet er svært ubalansert (~24:1), er presisjons–gjenfinningskurven den mest informative diagnosen — ROC AUC kan være misvisende optimistisk i ubalanserte innstillinger.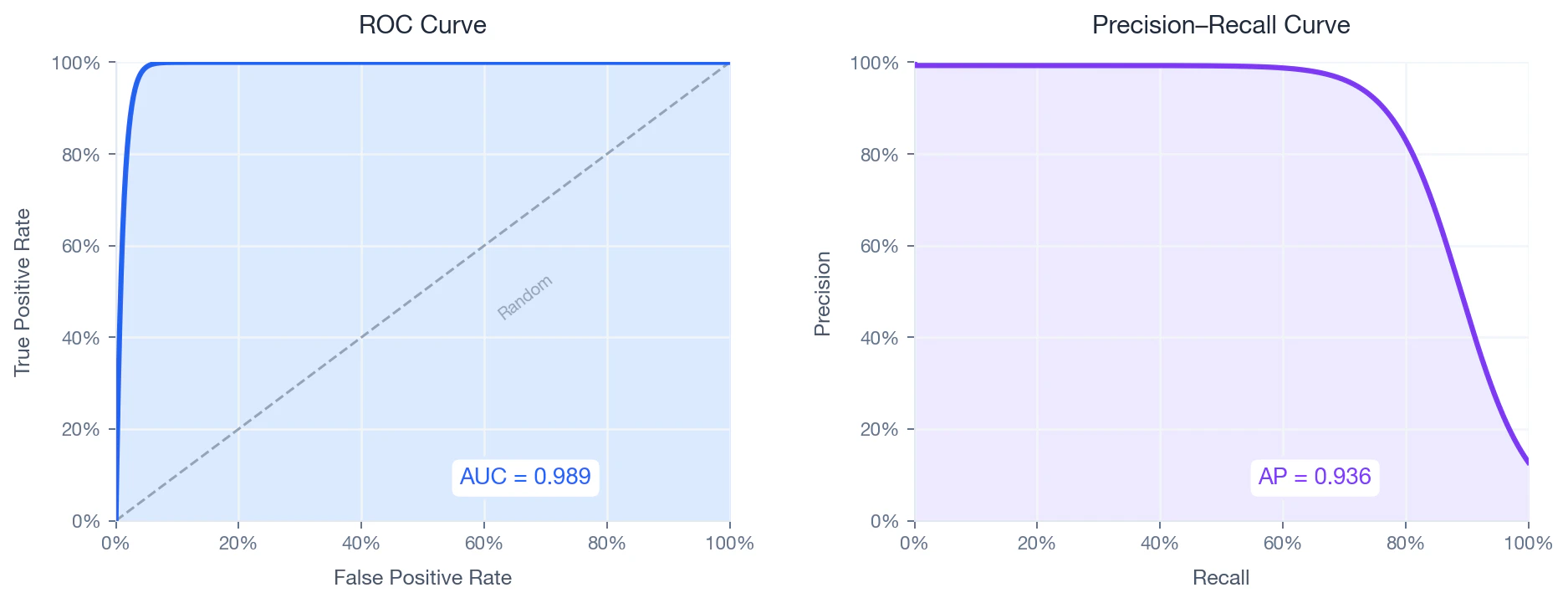
ROC curve (left) and Precision–Recall curve (right) on the held-out test set.
ROC-kurve
Hva det måler: hvor godt modellen skiller treff fra ikke-treff på tvers av alle mulige terskler. Diagrammet «ROC-kurve» viser sann positiv rate mot falsk positiv rate når terskelen går fra 1 til 0:Presisjon–gjenfinningskurve
Hva det måler: hvor mye presisjon modellen beholder når den gjenfinner flere treff. [Gjennomsnittlig presisjon (AP)](https://en.wikipedia.org/wiki/Evaluation_measures_\(information_retrieval\) #Average_precision) oppsummerer dette som det vektede arealet under PR-kurven:- — gjenfinning ved terskeltrinn
- — presisjon ved terskeltrinn
Avveining mellom presisjon og dekning
Hva det måler: Presisjon er andelen av predikerte treff som faktisk er korrekte. Dekning er andelen av inndata-navnene som får et treff over terskelen :- — antall navn som scorer på eller over
- — totalt antall innlagte navn
- Økning — færre navn som samsvarer, høyere presisjon, lavere dekning
- Senking — flere navn som samsvarer, lavere presisjon, høyere dekning
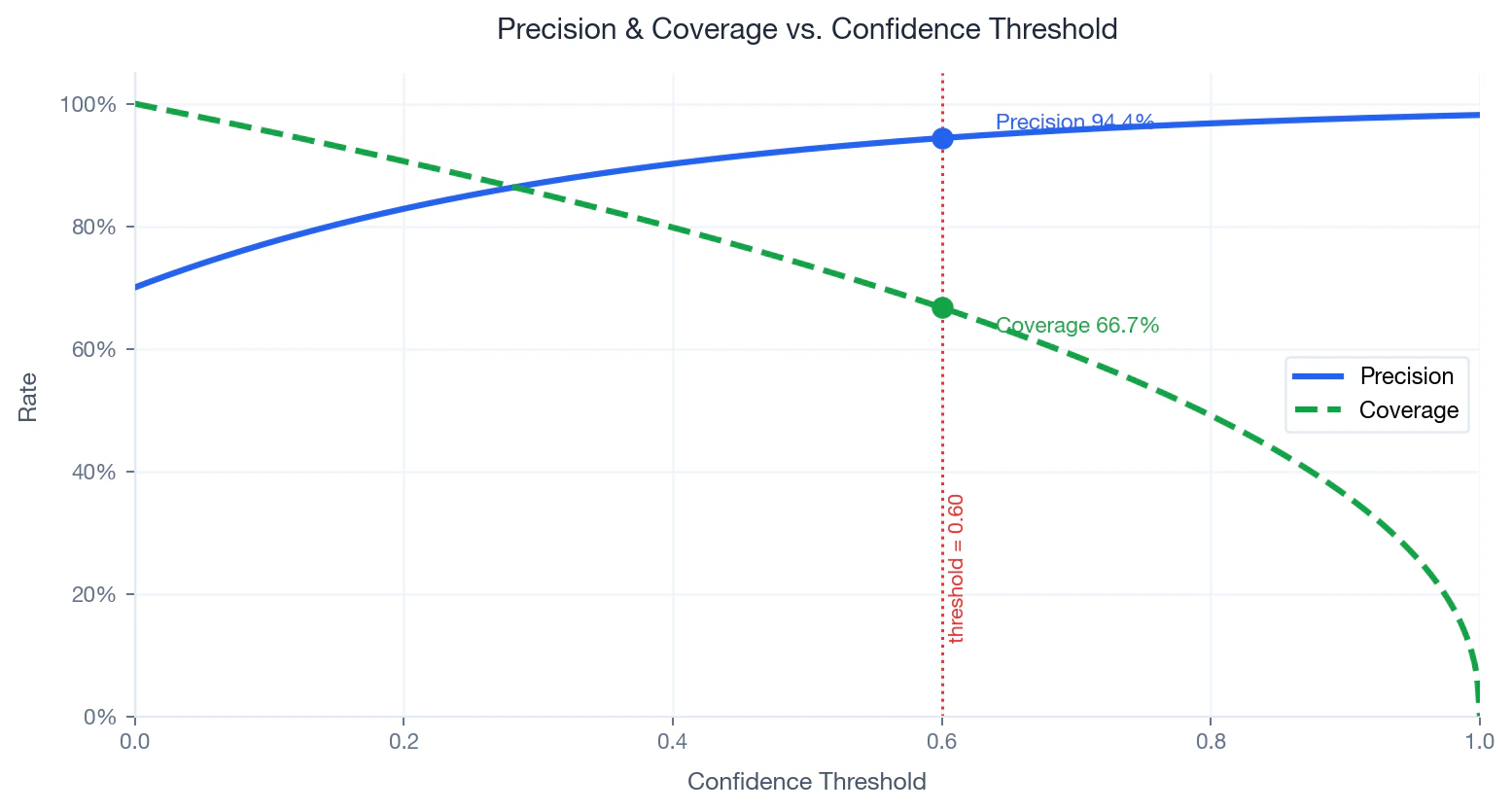
Precision and coverage as a function of confidence threshold. Operating point at 0.60 marked.