

Set di dati
Le prestazioni vengono valutate su un insieme di nomi di entità tenuti da parte, che sono stati deliberatamente esclusi dalla fase di addestramento affinché il modello non li abbia mai osservati. Tale procedura garantisce che la valutazione rifletta la capacità di generalizzazione del modello, e non una semplice memorizzazione. Per ciascun nome, la fase di recupero restituisce circa 25 candidati dal database Credit Benchmark. Le prestazioni vengono misurate a livello di coppia candidato-nome: ogni combinazione nome-candidato costituisce un esempio etichettato.
Poiché solo un candidato per nome è corretto, il set di dati risulta fortemente sbilanciato, riflettendo la distribuzione reale che il modello incontra in produzione. Le prestazioni vengono rivalutate ad ogni ciclo di riaddestramento settimanale.
Matrice di confusione
Cosa misura: L’Matrice di confusione e valuta il modello come un classificatore binario alla soglia I candidati al di sopra della soglia vengono considerati corrispondenze; tutti gli altri, non corrispondenze. Risultato:Vero positivo — 1.291
83.61% delle corrispondenze effettive identificate correttamente
Falsi positivi: 110
0.29% di effettivi casi di mancata corrispondenza segnalati erroneamente.
Falsi negativi — 253
16.39% Le corrispondenze effettive al di sotto della soglia vengono segnalate per ulteriore revisione.
Vero negativo — 37.397
99.71% di effettivi non corrispondenti correttamente scartati
- Su 1.544 abbinamenti corretti presenti nel set di test, 1.291 hanno ottenuto un punteggio superiore alla soglia. I 253 falsi negativi rappresentano corrispondenze che hanno ottenuto un punteggio inferiore alla soglia di confidenza dell’0.6.
- In pratica, Credit Benchmark osserva che la corrispondenza effettiva risulta comunque nel set di output, anche quando l’affidabilità della corrispondenza corretta è inferiore a 0,6.
- F1 è la media armonica di Ricordo e Precisione, e penalizza lo squilibrio tra le due metriche, premiando i modelli che ottengono buoni risultati su entrambi. Un punteggio F1 pari a alla soglia attesta un’elevata capacità di classificazione: il modello individua la maggior parte delle corrispondenze vere limitando al contempo le previsioni errate.
Curva ROC e precisione-richiamo
Poiché il set di dati è fortemente sbilanciato (rapporto circa 24:1), la curva Precisione-Richiamo rappresenta l’indicatore più informativo — L’AUC della curva ROC può risultare ingannevolmente ottimistica in contesti sbilanciati..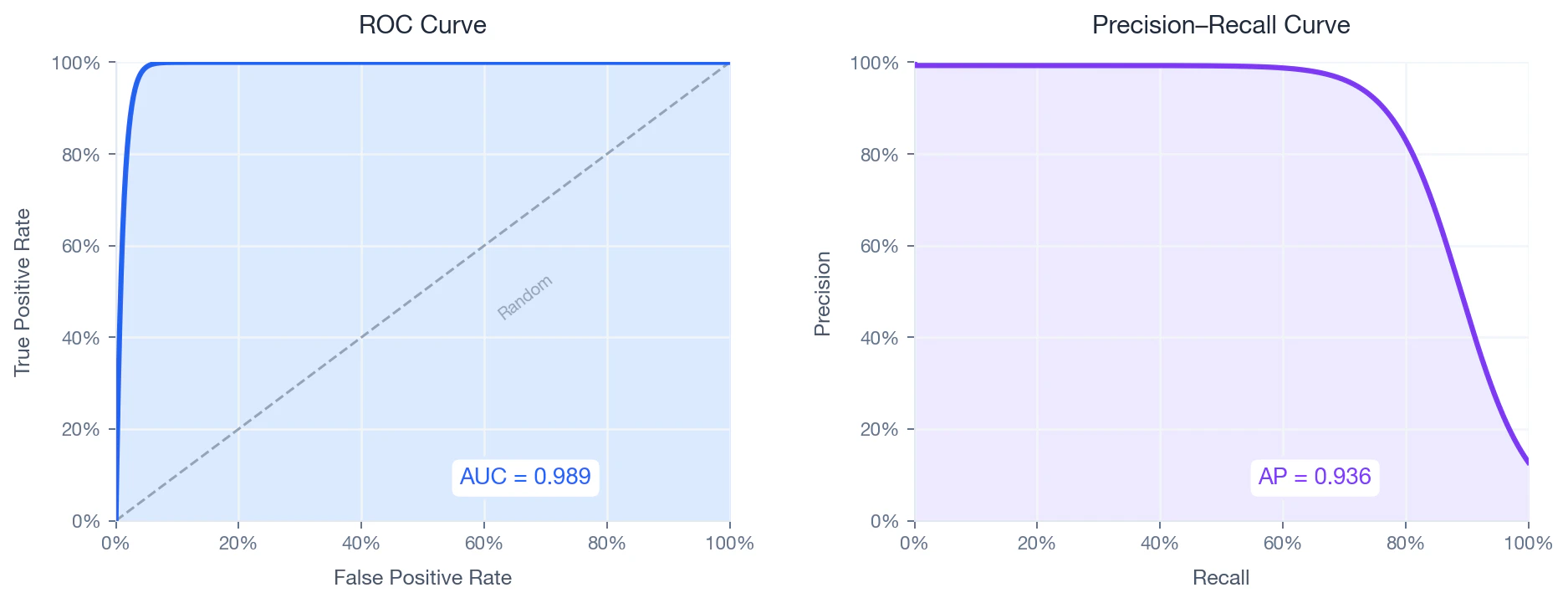
ROC curve (left) and Precision–Recall curve (right) on the held-out test set.
Curva ROC
Cosa misura: l’efficacia con cui il modello separa le corrispondenze dai non corrispondenti per tutte le soglie possibili. Il grafico “Curva ROC” (tasso di veri positivi contro tasso di falsi positivi) rappresenta il tasso di veri positivi in funzione del tasso di falsi positivi mentre la soglia varia da 1 a 0:Curva precisione-richiamo
Cosa misura: quanta precisione mantiene il modello man mano che recupera più corrispondenze. [Precisione media (AP)](https://en.wikipedia.org/wiki/Evaluation_measures_\(information_retrieval\) #Average_precision) riassume questo concetto come l’area ponderata sotto la curva PR:- — richiamo al livello di soglia
- — precisione al livello di soglia
Compromesso tra precisione e copertura
Cosa misura: Precisione è la percentuale di corrispondenze previste che sono effettivamente corrette. La copertura è la percentuale di nomi inseriti che ricevono una corrispondenza superiore alla soglia. :- — numero di nomi con punteggio pari o superiore a
- — numero totale di nomi inseriti
- Aumento — meno nomi corrispondenti, maggiore precisione, minore copertura
- Abbassamento — più nomi corrispondenti, minore precisione, maggiore copertura
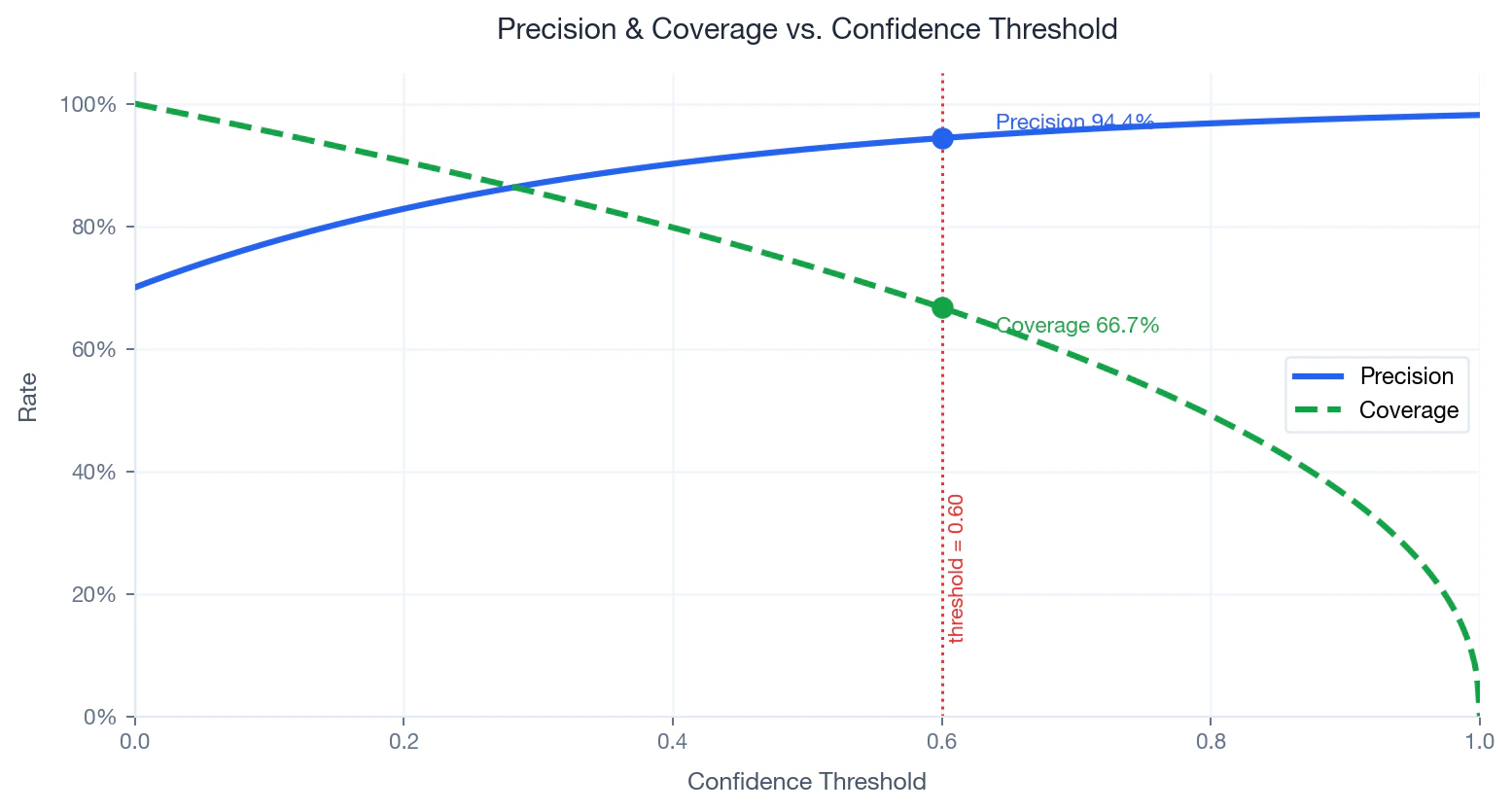
Precision and coverage as a function of confidence threshold. Operating point at 0.60 marked.