

Ensemble de données
La performance est mesurée sur un ensemble de noms d’entités mis de côté — des noms délibérément exclus de l’apprentissage afin que le modèle ne les ait jamais vus. Cela garantit que l’évaluation reflète la généralisation, et non la mémorisation. Pour chaque nom, l’étape de recherche renvoie environ 25 candidats issus de la base de données CB. La performance est mesurée au niveau des paires candidat-nom — chaque combinaison nom-candidat constitue un exemple étiqueté.
Comme un seul candidat par nom est pertinent, l’ensemble de données est fortement déséquilibré, reflétant la distribution réelle que le modèle rencontre en production. Les performances sont réévaluées à chaque cycle hebdomadaire de réentraînement.
Matrice de confusion
Ce qu’il mesure : L’Matrice de confusion e évalue le modèle en tant que classificateur binaire au seuil Les entités dont le score dépasse ce seuil sont alors considérées comme des correspondances ; les autres sont classées comme non-correspondances. Résultat :Vrais positifs — 1 291
83.61% des correspondances réelles correctement identifiées.
Faux positifs — 110
0.29% des non-correspondances réelles signalées à tort.
Faux négatifs : 253
16.39% Les correspondances réelles situées sous le seuil sont mises en évidence pour examen.
Vrais négatifs — 37 397
99.71% Les non-correspondances réelles sont correctement rejetées.
- Sur les 1 544 correspondances réelles de l’ensemble de test, 1 291 ont obtenu un score supérieur au seuil.
- Les 253 faux négatifs correspondent à des correspondances dont le score était inférieur au seuil de confiance de l’0.6.
- En pratique, Credit Benchmark constate que la correspondance réelle apparaît toujours dans l’ensemble de résultats — même lorsque le niveau de confiance pour la correspondance correcte est inférieur à 0,6.
- Le F1, moyenne harmonique du rappel et de la précision, pénalise tout déséquilibre entre ces deux mesures et récompense les modèles qui obtiennent de bons résultats sur les deux plans.
- Un score F1 de 87.7% atteste d’une performance globale de classification au seuil d’0.60, le modèle récupérant la grande majorité des correspondances réelles tout en produisant peu de prédictions erronées.
Courbe ROC et précision-rappel
Comme l’ensemble de données est fortement déséquilibré (~24:1), la courbe précision-rappel constitue le diagnostic le plus informatif — L’AUC de la courbe ROC peut s’avérer trompeusement optimiste dans des contextes déséquilibrés..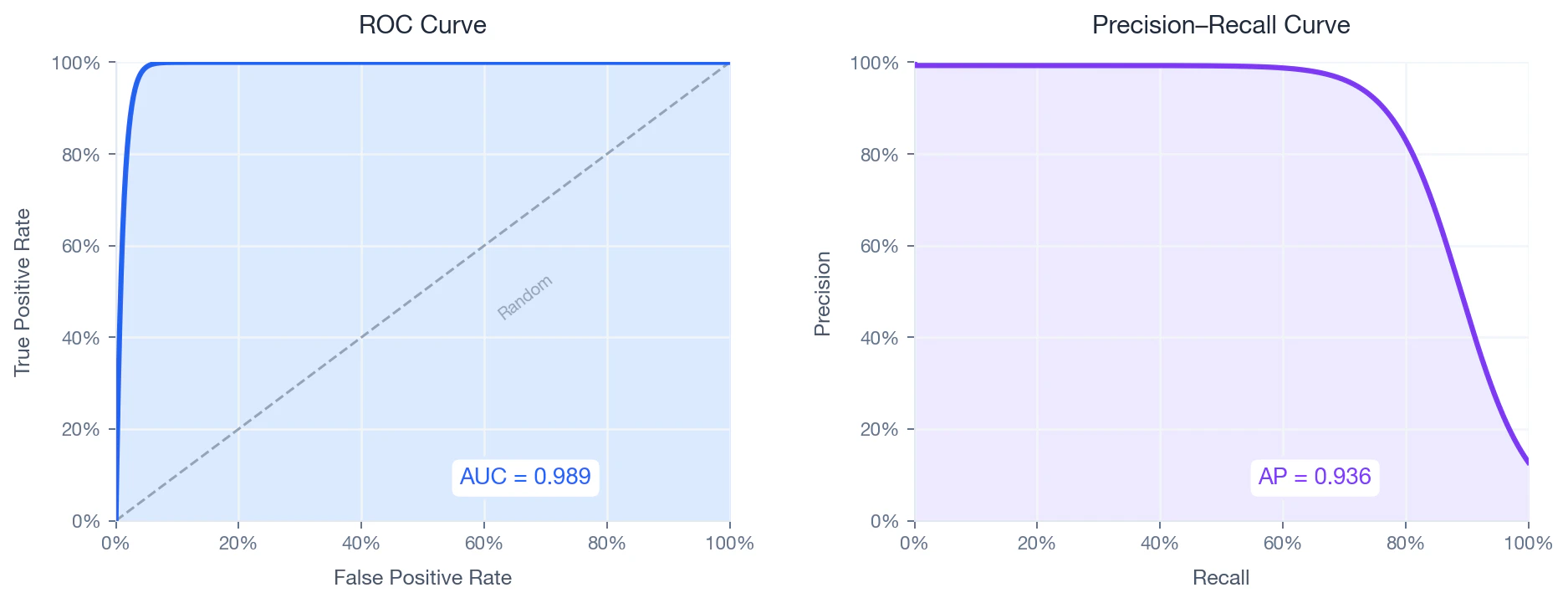
ROC curve (left) and Precision–Recall curve (right) on the held-out test set.
Courbe ROC
Ce qu’il mesure : la capacité du modèle à distinguer les correspondances des non-correspondances pour tous les seuils possibles. L’Courbe ROC e représente le taux de vrais positifs en fonction du taux de faux positifs à mesure que le seuil varie de 1 à 0 :Courbe précision-rappel
Ce qu’il mesure : le niveau de précision que le modèle conserve à mesure qu’il identifie davantage de correspondances. [Précision moyenne (AP)](https://en.wikipedia.org/wiki/Evaluation_measures_\(information_retrieval\) #Average_precision) résume cela par l’aire pondérée sous la courbe PR :- — rappel au seuil
- — précision au seuil
Compromis entre précision et couverture
Ce qu’il mesure : Précision est la part de correspondances prédites qui s’avèrent exactes. La couverture représente la part de noms saisis obtenant une correspondance supérieure au seuil. :- — nombre de noms obtenant un score égal ou supérieur à
- — nombre total de noms saisis
- Augmentation — moins de noms correspondants, précision plus élevée, couverture plus faible
- Réduction — davantage de noms correspondants, précision plus faible, couverture plus élevée
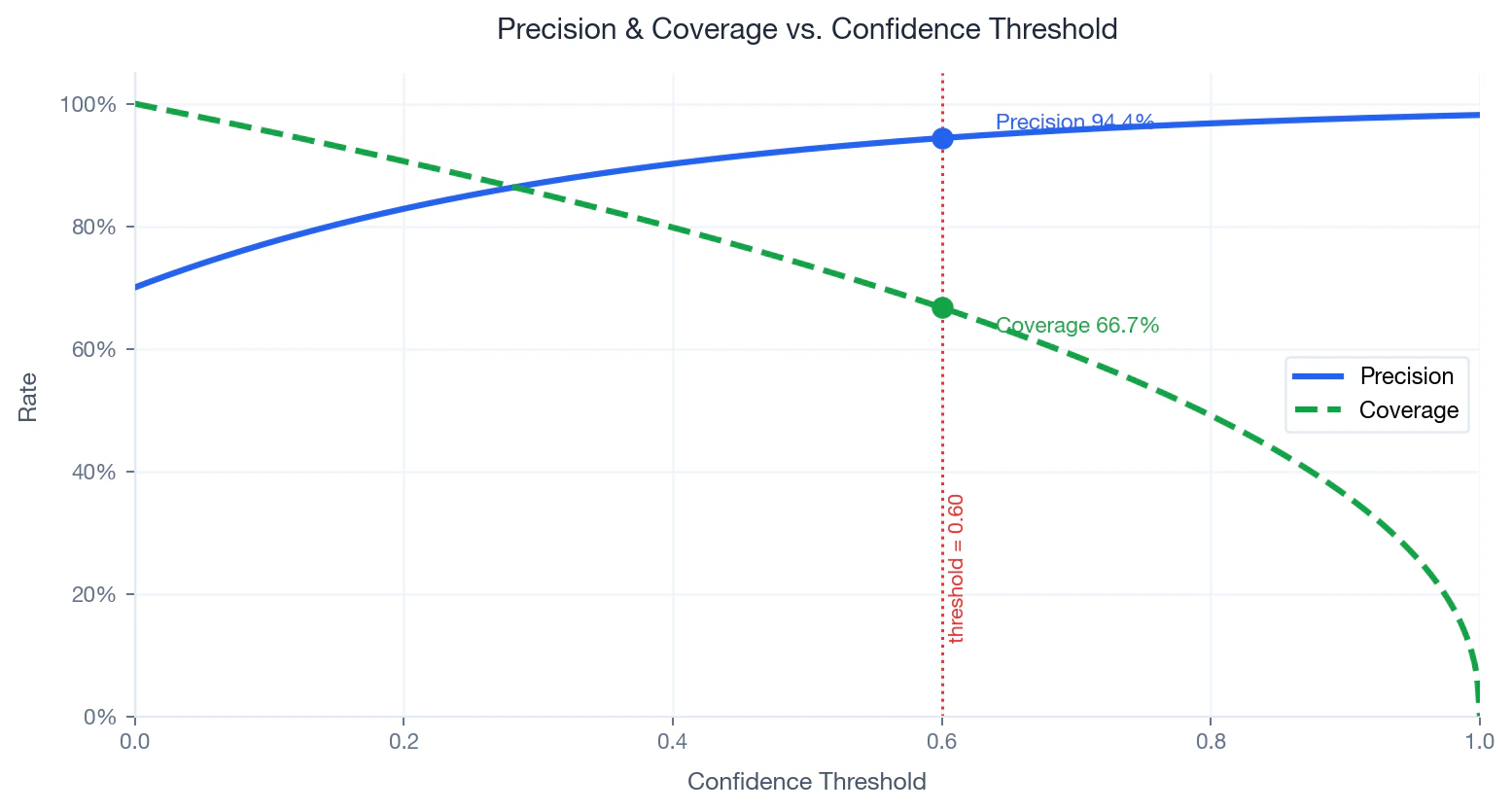
Precision and coverage as a function of confidence threshold. Operating point at 0.60 marked.