

Dataset
Performance is measured on a held-out set of entity names — names deliberately excluded from training so the model has never seen them. This ensures evaluation reflects generalisation, not memorisation. For each name, the retrieval stage returns ~25 candidates from the CB database. Performance is measured at the candidate-pair level — each name–candidate combination is one labelled example.
Because only one candidate per name is correct, the dataset is heavily imbalanced — mirroring the real-world distribution the model encounters in production. Performance is re-evaluated with each weekly retraining cycle.
Confusion Matrix
What it measures: The confusion matrix evaluates the model as a binary classifier at threshold . Candidates above the threshold are predicted as matches; all others as non-matches. Result:True Positive — 1,291
83.61% of actual matches correctly identified
False Positive — 110
0.29% of actual non-matches incorrectly flagged
False Negative — 253
16.39% of actual matches below threshold — surfaced for review
True Negative — 37,397
99.71% of actual non-matches correctly rejected
- Of the 1,544 true matches in the test set, 1,291 scored above threshold.
- The 253 false negatives represent matches that were scored below the 0.6 confidence threshold.
- In practice, Credit Benchmark finds that the true match is still surfaced in the result set — even when the confidence for the correct match is lower than 0.6.
- F1 is the harmonic mean of Recall and Precision — it penalises imbalance between the two, rewarding models that perform well on both.
- An F1 of 87.7% reflects strong overall classification performance at the 0.60 threshold — the model recovers the large majority of true matches while producing few incorrect predictions.
ROC Curve & Precision–Recall
Because the dataset is heavily imbalanced (~24:1), the Precision–Recall curve is the more informative diagnostic — ROC AUC can be misleadingly optimistic in imbalanced settings.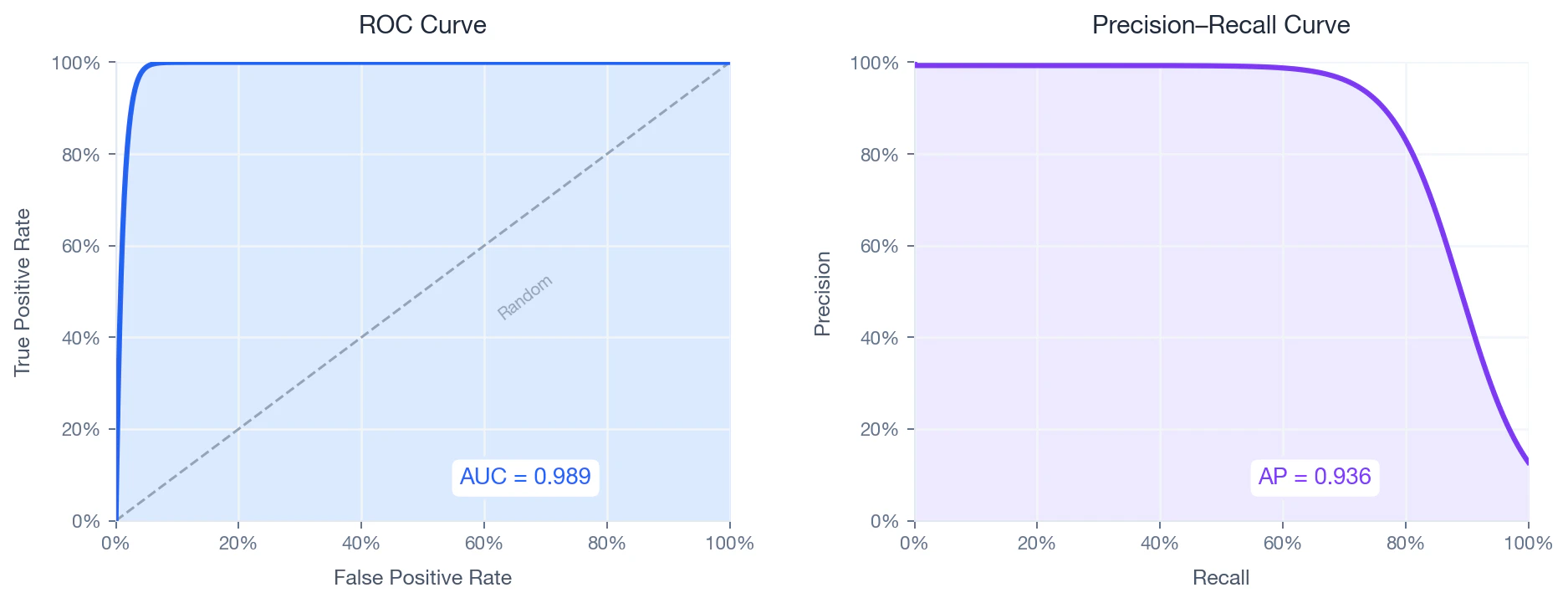
ROC curve (left) and Precision–Recall curve (right) on the held-out test set.
ROC Curve
What it measures: how well the model separates matches from non-matches across all possible thresholds. The ROC curve plots True Positive Rate against False Positive Rate as the threshold sweeps from 1 to 0:Precision–Recall Curve
What it measures: how much precision the model retains as it recovers more matches. Average Precision (AP) summarises this as the weighted area under the PR curve:- — recall at threshold step
- — precision at threshold step
Precision–Coverage Trade-off
What it measures: Precision is the share of predicted matches that are actually correct. Coverage is the share of input names that receive a match above threshold :- — number of names scoring at or above
- — total number of input names
- Raising — fewer names matched, higher precision, lower coverage
- Lowering — more names matched, lower precision, higher coverage
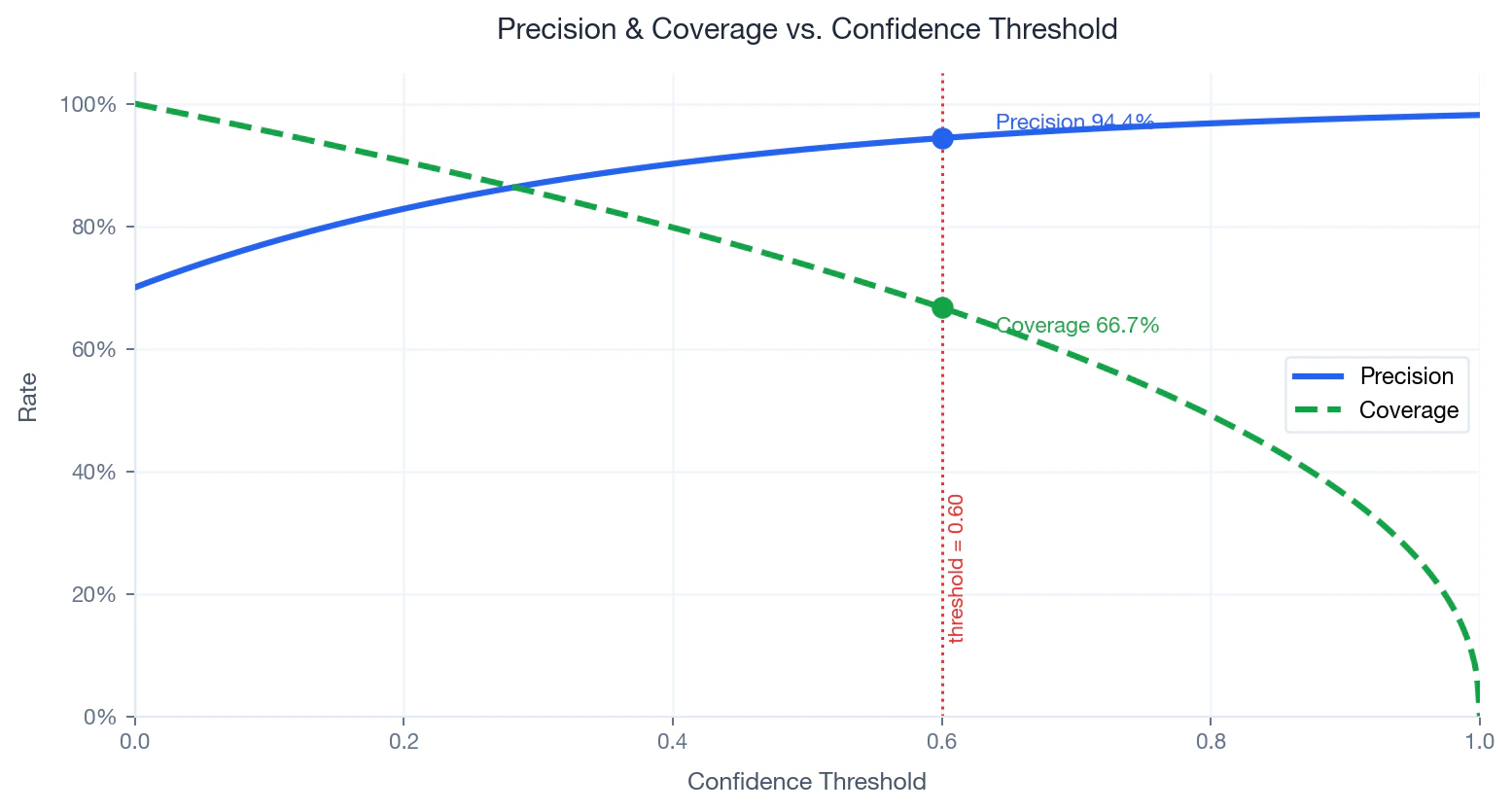
Precision and coverage as a function of confidence threshold. Operating point at 0.60 marked.